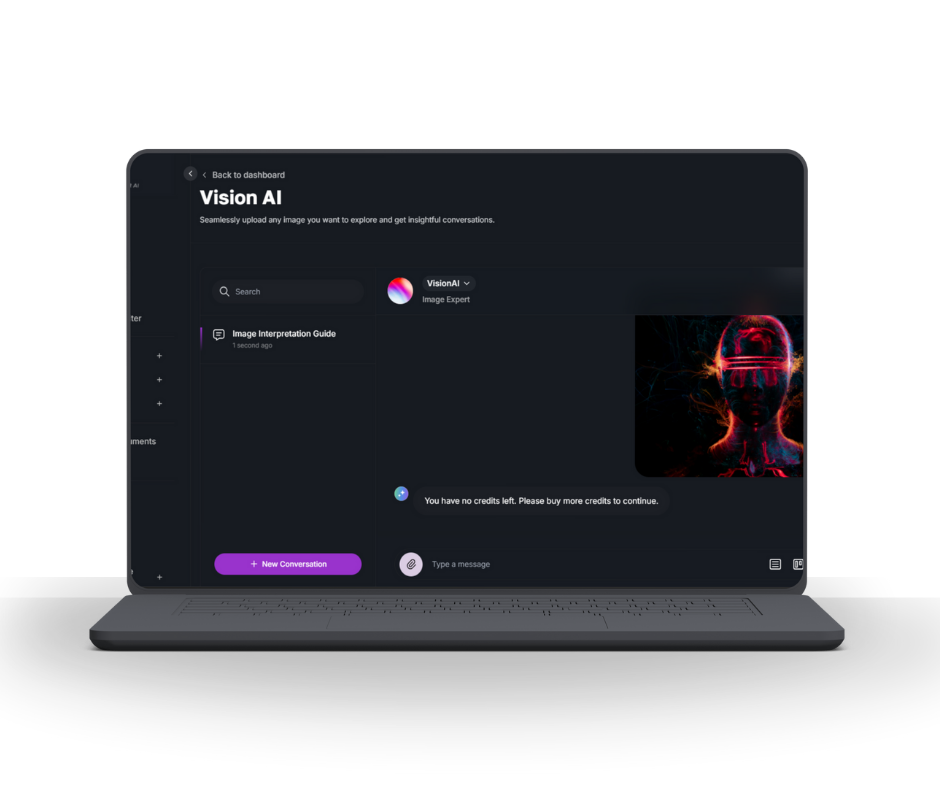
Vision AI allows users to upload any image—from a document or a product mockup to a meme, screenshot, or photo—and receive detailed, intelligent responses based on the visual content. Whether users are analyzing diagrams, extracting text, identifying patterns, or just asking questions about what’s in the image, Vision AI responds with precision and clarity.
Once an image is uploaded, the system uses multimodal AI models to “see” and understand it. Users can then type questions or prompts related to the image, and Vision AI provides natural-language answers with relevant context. It’s like combining OCR, object detection, and an intelligent assistant in one seamless workflow.
We developed the Vision AI interface for LuxAI to turn images into a source of deep, interactive insight. This build was centered around clarity, minimalism, and fast performance—allowing users to effortlessly upload visuals and receive smart, contextual feedback in real time. It’s not just a tool; it’s a way to have meaningful conversations with your images.
Under the Hood
Where Vision AI really shines is in its ability to interpret complex visuals through conversation. Users can ask follow-up questions, request summaries, or zoom in on specific parts of the content—making it ideal for workflows like:
Reading and summarizing documents
Analyzing screenshots and wireframes
Explaining UI layouts or app screens
Describing charts, diagrams, or presentations
Extracting text or tabular data from visuals
The interface is clean and distraction-free, ensuring the focus stays on the image and the conversation. For professionals, researchers, marketers, and designers alike, Vision AI transforms static content into a dynamic, explorable experience—no manual analysis needed.